Diffusion models
Modelos de Difusão em World Foundation Models (WFMs)
No contexto dos World Foundation Models (WFMs), ele transforma ruído em uma simulação de vídeo do mundo.
Analogia: "Pense em um modelo de difusão como um artista que começa com uma tela cheia de ruído aleatório (como uma "chuva" de TV antiga) e, gradualmente, passo a passo, aprende a remover esse ruído, revelando uma imagem ou vídeo coerente e significativo."
Tokenização de Vídeo: Transformando Vídeos em "Latentes Contínuos"
Assim como os modelos autoregressivos, os modelos de difusão precisam processar vídeos em um formato mais gerenciável para sua operação.
-
Tokens Contínuos: Para modelos de difusão, os vídeos são transformados em embeddings latentes contínuos (vetores de números decimais). Pense neles como uma representação compacta e fluida do vídeo, em oposição aos "tokens discretos" (números inteiros) usados pelos modelos autoregressivos.
-
Cosmos Continuous Tokenizer (Cosmos-1.0-Tokenizer-CV8x8x8): Este é o componente responsável por essa transformação. Ele comprime o vídeo de entrada em uma representação latente de menor dimensão, preservando a maior parte da informação visual. Este tokenizer possui uma arquitetura de codificador-decodificador que opera no espaço wavelet para maior compressão e preservação de informações semânticas, além de um design causal temporal (a codificação de quadros atuais não depende de quadros futuros, crucial para aplicações de IA Física).
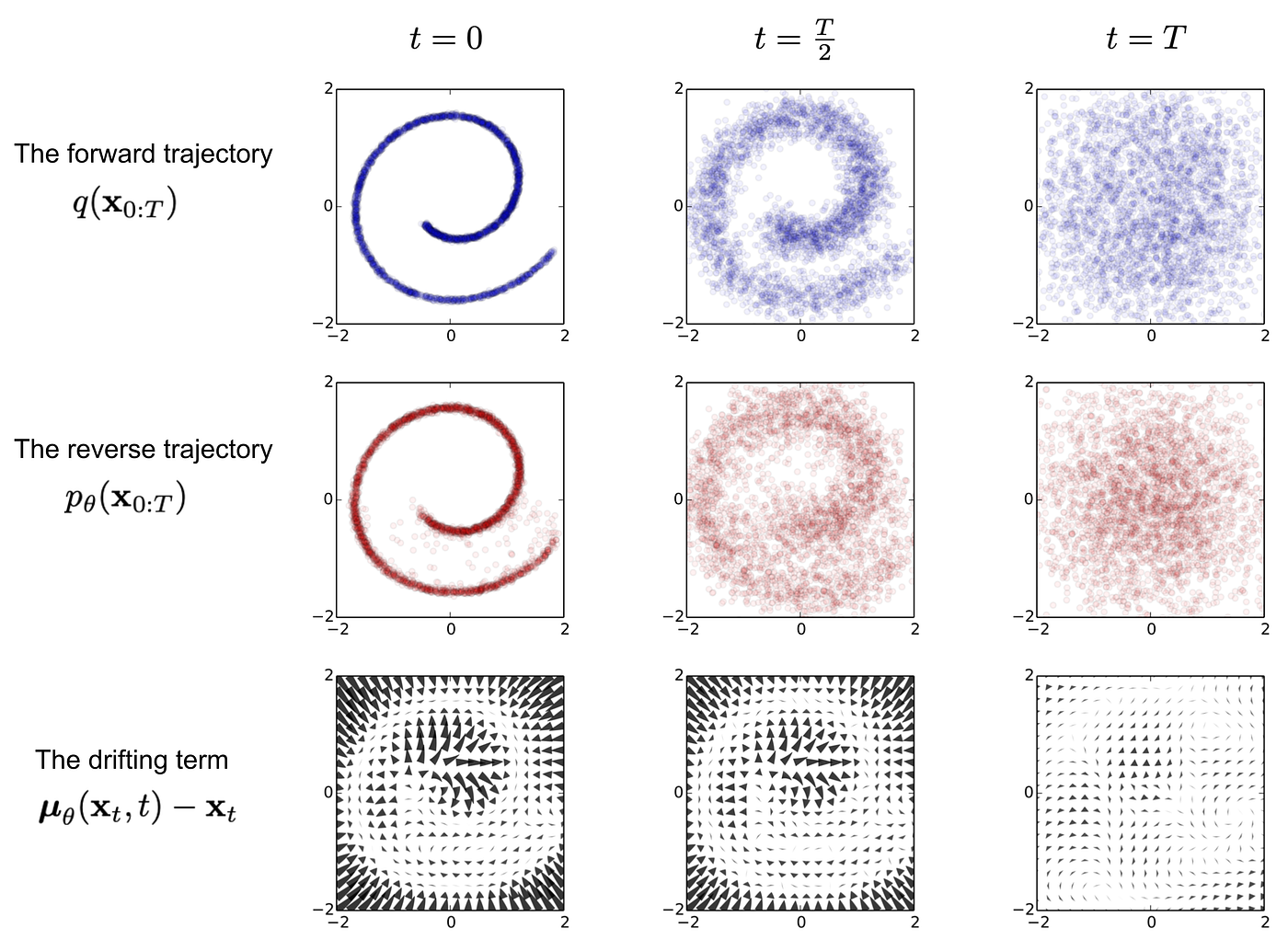
Formulação: O Processo de Denoising (Remoção de Ruído)
O cerne do modelo de difusão é o processo iterativo de "denoising" (remoção de ruído).
Detalhes da Formulação
| Aspecto | Descrição |
|---|---|
| Adição e Remoção de Ruído | Durante o treinamento, ruído gaussiano (aleatório) é progressivamente adicionado a um vídeo real. O modelo é, então, treinado para inverter esse processo, aprendendo a remover o ruído em cada etapa para reconstruir o vídeo original a partir de uma versão ruidosa. |
| Função Denoising (D_theta) | O modelo de difusão utiliza uma rede neural D_theta (chamada "denoiser") treinada para estimar o ruído presente em uma amostra corrompida (vídeo com ruído) e, consequentemente, removê-lo para chegar à versão limpa do vídeo. |
| Função de Perda | O treinamento emprega uma função de perda de "denoising score matching" que penaliza a diferença entre o ruído previsto pelo modelo e o ruído real adicionado. Uma técnica de ponderação baseada em incerteza (mu(sigma)) é utilizada para gerenciar o aprendizado em diferentes níveis de ruído, tratando-o como um problema de aprendizado multi-tarefa. |

Arquitetura do Modelo: Como o Denoising é Construído
A rede D_theta do modelo de difusão é uma adaptação de uma arquitetura Transformer, otimizada para dados visuais e controle.
Componentes Arquitetônicos Chave
| Componente | Descrição |
|---|---|
| Patchificação 3D | As representações latentes de entrada são convertidas em "patches" (pedaços cúbicos) tridimensionais, que são então "achatados" em uma sequência unidimensional. Isso prepara os dados para serem processados eficientemente pelo Transformer. |
| Embeddings Posicionais Híbridos | Essenciais para a compreensão espacial e temporal: • Rotary Position Embedding (RoPE) Fatorado em 3D: Ajuda o modelo a entender as posições relativas dos tokens nas dimensões temporal, de altura e de largura, permitindo a geração de vídeos de tamanhos e durações arbitrárias, compatível com diferentes taxas de quadros (FPS). • Embedding Posicional Absoluto (Aprendível): Um embedding adicional usado em cada bloco Transformer que, combinado com RoPE, melhora o desempenho, reduz a perda de treinamento e minimiza artefatos de "morphing". |
| Cross-Attention para Condicionamento de Texto | Camadas integradas que permitem ao modelo gerar vídeos com base em descrições de texto, incorporando informações de embeddings de texto (gerados pelo T5-XXL) no processo de denoising. |
| QK-Normalização (QKNorm) | Normaliza os vetores de "query" (Q) e "key" (K) antes da operação de atenção, o que aumenta a estabilidade do treinamento, especialmente nas fases iniciais, prevenindo a saturação da atenção. |
| AdaLN-LoRA | Uma otimização arquitetônica que reduz significativamente a contagem de parâmetros (ex: 36% para o modelo de 7B parâmetros) sem comprometer o desempenho, tornando o modelo mais eficiente em termos de memória e computação. |
Estratégia de Treinamento: Como o Modelo Aprende a "Pintar"
Os modelos de difusão são treinados em várias etapas para otimizar seu desempenho e generalização.
| Aspecto | Descrição |
|---|---|
| Treinamento Conjunto Imagem e Vídeo | Para alavancar a vasta quantidade de dados de imagens, uma estratégia de otimização alternada intercala lotes de dados de imagem e vídeo. É usada uma normalização específica de domínio para alinhar as distribuições latentes e encorajar uma representação isotrópica gaussiana. A perda de denoising para vídeos é escalonada para lidar com a convergência mais lenta. |
| Treinamento Progressivo | O modelo é treinado progressivamente, iniciando com resoluções e durações de vídeo menores (ex: 512p com 57 quadros) e avançando para resoluções e durações maiores (ex: 720p com 121 quadros). Uma fase de "resfriamento" (cooling-down) com dados de alta qualidade e uma taxa de aprendizado decrescente refina ainda mais o modelo. |
| Treinamento Multi-Aspecto | Os dados são organizados em "buckets" com base em suas proporções de aspecto (ex: 1:1, 16:9) para acomodar a diversidade de conteúdo. Preenchimento (padding) com reflexão é usado para pixels ausentes durante o processamento em lote. |
| Treinamento com Precisão Mista | Para eficiência, os pesos do modelo são mantidos em BF16 e FP32. O BF16 é usado para os passes de forward e backward, e o FP32 para as atualizações de parâmetros, garantindo estabilidade numérica. |
| Condicionamento de Texto | Utiliza o T5-XXL como codificador de texto. Modelos Text2World são capazes de gerar vídeo a partir de uma entrada textual. |
| Condicionamento de Imagem e Vídeo (Video2World) | Modelos Video2World estendem os modelos Text2World para aceitar quadros anteriores (imagem ou vídeo) como condição para gerar quadros futuros. Ruído adicional é introduzido nos quadros condicionais durante o treinamento para aumentar a robustez. |
Otimização de Inferência: Tornando a Geração Rápida
Embora os modelos de difusão sejam inerentemente mais lentos devido ao seu processo iterativo de denoising, otimizações significativas são aplicadas para acelerar a geração.
Técnicas de Otimização de Inferência
| Técnica | Descrição |
|---|---|
| FSDP (Fully Sharded Data Parallelism) | Distribui os parâmetros do modelo, gradientes e estados do otimizador por múltiplos dispositivos (GPUs), resultando em significativa economia de memória e permitindo o uso de modelos maiores. |
| Context Parallelism (CP) | Divide a computação e as ativações ao longo da dimensão da sequência, distribuindo-as entre GPUs. Esta técnica é crucial para lidar com contextos longos de vídeo, onde a quantidade de dados a ser processada é muito grande. |
Prompt Upsampler: Para Entradas de Texto do Usuário
-
Para preencher a lacuna entre as prompts de texto curtas e variadas fornecidas pelos usuários e as descrições de vídeo detalhadas usadas no treinamento dos WFMs, um "Prompt Upsampler" é desenvolvido.
-
Ele transforma as prompts originais em versões mais detalhadas e ricas que se alinham com a distribuição das prompts de treinamento, melhorando a qualidade do vídeo gerado. Para modelos Text2World, o Mistral-NeMo-12B-Instruct é usado para isso; para Video2World, o Pixtral-12B é utilizado.
Decodificador de Difusão: Melhorando a Qualidade Visual do Autoregressivo
Embora este seja uma parte do modelo de difusão, ele tem um papel especial de pós-otimização para outros modelos:
-
Para os modelos autoregressivos (que podem gerar vídeos borrados devido à tokenização agressiva), um decodificador de difusão mais poderoso é usado como uma "pós-otimização".
-
Este decodificador pega os tokens discretos (saída do modelo autoregressivo) e os "traduz" de volta para tokens contínuos de maior qualidade, que são então convertidos em vídeos RGB de alta qualidade. É como refinar um rascunho em uma obra de arte acabada.
Equações
Perda do Denoising: ℒ(𝐷𝜃, 𝜎) = Ex0,n [︁⃦⃦ 𝐷𝜃(x0 + n;𝜎)− x0 ⃦⃦2 2 ]︁
x0 (lê-se "x zero"): Representa o vídeo original, limpo (a "tela perfeita")n: Representa o ruído gaussiano aleatório que foi adicionado ao vídeo x0𝜎 (sigma): Indica o nível de ruído naquele momento. Vídeos com mais ruído terão um 𝜎 maior.x0 + n: É o vídeo com ruído (a "tela suja") que é dado como entrada para o nosso modelo𝐷𝜃: É a nossa rede neural "denoiser". O 𝜃 (theta) representa todos os parâmetros (pesos) que a rede precisa aprender durante o treinamento𝐷𝜃(x0 + n;𝜎): É o que o modelo 𝐷𝜃 prevê que seja o vídeo original limpo (x0), dado o vídeo ruidoso (x0 + n) e o nível de ruído (𝜎)𝐷𝜃(x0 + n;𝜎)− x0: Esta é a diferença entre o que o modelo previu e o vídeo real e limpo (x0)... ⃦⃦2 2 ]︁: Isso significa o quadrado da norma L2, que é uma forma de medir a "distância" ou o "erro" entre a previsão do modelo e a realidade. Basicamente, estamos pegando a diferença, elevando ao quadrado (para que valores negativos e positivos contem igualmente) e somando tudo. Queremos que esse erro seja o menor possívelE_x0,n [ ... ]: Significa a esperança (ou média) sobre diferentes vídeos limpos (x0) e diferentes tipos de ruído (n)
Perda total de Treinamento: ℒ(𝐷𝜃) = E𝜎 [ 𝜆(𝜎) ℒ(𝐷𝜃, 𝜎) + 𝑢(𝜎) ]
E𝜎 [ ... ]: Significa a esperança (média) sobre diferentes níveis de ruído (𝜎). O modelo é treinado para lidar com todos os níveis de ruído, do quase limpo ao totalmente ruidoso.𝜆(𝜎) (lambda de sigma): É uma função de ponderação. Ela ajusta a importância de cada nível de ruído (𝜎) na perda total, para que o modelo preste atenção a todos eles. Inicialmente, ela garante que todos os níveis de ruído contribuam igualmente para o aprendizado.𝑢(𝜎) (u de sigma): É uma função de incerteza contínua. O modelo também aprende essa função. Se o modelo está "incerto" sobre como remover o ruído em um certo nível 𝜎, ele se penaliza, incentivando-o a reduzir essa incerteza. Isso ajuda a otimização em diferentes níveis de ruído, tratando-os como um problema de aprendizado multi-tarefa
Função de Ponderação: 𝜆(𝜎) = (︀ 𝜎2 + 𝜎2data )︀ / (𝜎 · 𝜎data)
𝜎data: É o desvio padrão dos dados de treinamento. Essa equação define como o 𝜆(𝜎) calcula o peso de cada nível de ruído, inicialmente visando uma contribuição igualitária
Distribuição do Nível de Ruído: ln(𝜎) ∼ 𝒩 (︀ 𝑃mean, 𝑃 2std )︀
- Isso descreve como os níveis de ruído (𝜎) são escolhidos durante o treinamento. O logaritmo natural (ln) de 𝜎 segue uma distribuição normal (𝒩), com uma média (𝑃mean) e um desvio padrão (𝑃std) definidos. Isso garante que o modelo veja uma boa variedade de níveis de ruído
Resultados e Aplicações
Os modelos de difusão Cosmos-1.0 (7B e 14B) são capazes de gerar vídeos com alta qualidade visual, dinâmicas de movimento e alinhamento preciso com o texto. O modelo de 14B demonstra uma capacidade aprimorada de capturar detalhes visuais mais finos e padrões de movimento mais intrincados.
Eles são utilizados em diversas aplicações de IA Física, como:
-
Controle de Câmera: Permitem gerar mundos virtuais navegáveis com base em uma imagem de referência e trajetórias de câmera, mantendo a coerência 3D e temporal.
-
Manipulação Robótica: Podem ser ajustados para prever vídeos de robôs seguindo instruções de texto ou sequências de ações.
-
Condução Autônoma: São adaptados para criar modelos de mundo multi-visão para cenários de condução, gerando vídeos de seis câmeras simultaneamente e até seguindo trajetórias de veículos.
-
Modelos de difusão baseados em Transformer são frequentemente capazes de incorporar diversos sinais de controle.
-
As avaliações mostram que os WFMs baseados em difusão entregam melhor qualidade de geração e maior consistência 3D em comparação com as linhas de base e os modelos autoregressivos em certas condições.
Limitações
Apesar dos avanços, os modelos de difusão para simulação do mundo ainda enfrentam desafios comuns aos WFMs:
-
Falta de Permanência de Objetos: Objetos podem desaparecer ou aparecer inesperadamente.
-
Imprecisões em Dinâmicas com Contato: Interações físicas complexas, como colisões, ainda são difíceis de modelar com precisão.
-
Inconsistência no Seguimento de Instruções: O modelo nem sempre segue as instruções de texto de forma totalmente precisa.
-
Aderência às Leis da Física: A gravidade, interações de luz e dinâmicas de fluidos ainda não são perfeitamente simuladas.